



How to Build AI Software: The Complete 2026 Playbook
In 2023, developing AI software was about proving what was possible, usually by wiring a single model into a simple app. It is 2026, and the novelty has now shifted to necessity.
The question is more about how to design systems that remain reliable and context-aware on real-time operational data. The development of artificial intelligence software follows business functions, such as shifts in inventory levels or fluctuating market prices.
Early GenAI was a glorified search engine: fire a prompt, get a response, and forget. Today, stateful agents retain state and autonomously solve complex business logic.
UK data proves this: software accounted for 48.1% of the AI market as firms moved from trials to production.
In this AI software development playbook, we’ll explore how AI is defining the new reality.
The AI Engineering Playbook for 2026
Let’s take a detailed look at how AI software development will take shape in 2026, with a focus on building systems that hold up under real-world user conditions.
A. Define What You’re Actually Building
Before choosing a model or writing a line of code, know what you’re building. Developing AI software systems differ in their behaviour and responsibilities, with multiple steps that follow.
Clarify the AI Software Category you’re Building.
Artificial Intelligence software development requires determining the AI system’s category. Each of the following categories varies because it requires a fundamentally different architecture and risk model.
| System Category | Operational Focus | Real-World Application |
| Predictive Systems | Forecasting, scoring, and ranking based on historical patterns | Churn predictors, fraud scoring, and lead qualification |
| Generative Systems | Creating unique content, code, or conversational dialogue | Creative assistants with code generators and basic chatbots |
| Decision-Support | High-speed classification and intelligent routing | Ticket routing and clinical decision support |
| Autonomous Agents | Executing multi-step workflows through active tool use. | Refund handling agents, data analysis bots, support agents |
Translate the Problem into a Machine-usable Workflow
A move from prompt-based writing to logic mapping requires converting traditional, judgment-heavy SOPs into Agentic SOPs.
Transform a static document into a fixed sequence of machine-readable steps by providing predefined decision checkpoints with clear entry and exit points.
AI systems in 2026 depend on 3 structural elements:
- Workflow: Highlights a defined sequence of actions that determines what happens next and when execution ends. Usually, this means defining a Directed Acyclic Graph (DAG), which forces the AI to move from Step A to Step B linearly.
- Grounding: Provides access to trusted data to anchor AI to your live data. Instead of AI using its internal training to guess a price, it is forced to use a tool to fetch the current price from your SQL database.
- Guardrails: Enforce hard-coded constraints to ensure the AI stays within its sandbox.
Come Up with a Cognitive OOP (The “How-To” Core)
Building AI software requires a shift toward Agentic Object-Oriented Programming (OOP), in which an agent, as a stateful object, follows a cognitive OOP paradigm.
A structured cycle of reasoning and action mimics how a human professional completes a task, with each stage having a clear role.
| Stage | What Happens |
| Intent | The system identifies what the user is asking for and the context around it |
| Reasoning | A planning step where the model decides how to approach the task before acting |
| Tool Use | The system executes code, queries APIs, or calls internal services instead of relying on text alone. |
| Metacognition | The system reviews its own output, checks for errors, and adjusts before finalising a response. |
A simple workflow map makes this easier to visualise.
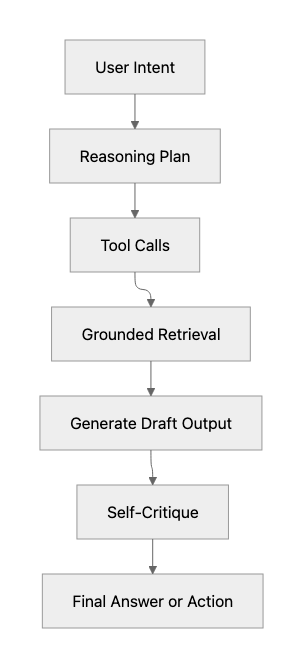
The execution loop remains explicit so that the AI no longer behaves like a black box. Instead, it acts like software with a traceable decision path.
B. Architecting AI Software Development in 2026
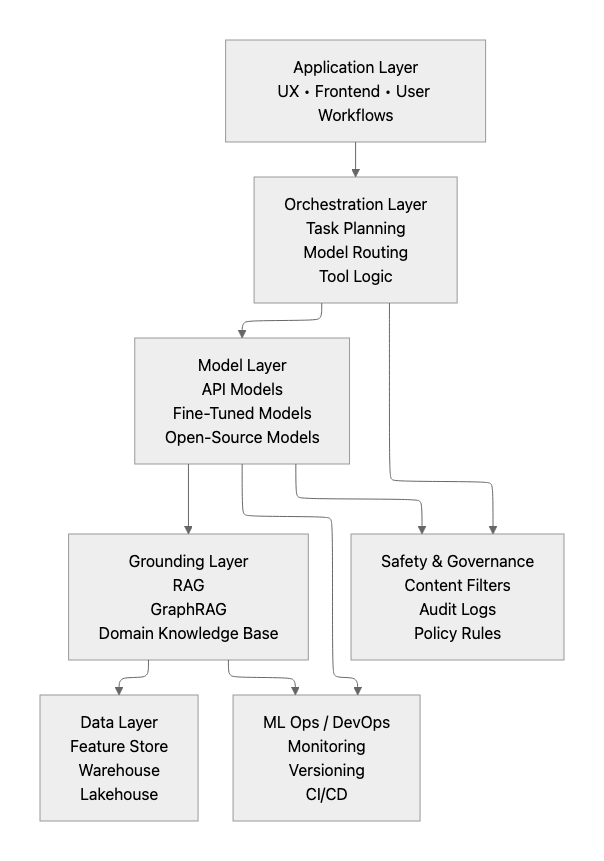
AI software architecture is multi-layered, having intelligence embedded within a larger system that must operate safely and predictably. This requires teams to move away from simple API calls towards architectures built for reliability.
The real challenge lies in coordination. AI software needs a structure that links user-facing workflows to models and data without becoming fragile. Each layer has a defined responsibility, and every handoff needs intent.
The diagram below shows how AI systems in 2026 are typically organised, from application logic at the top to data and operational layers beneath.
Creating Data Foundations
Decide what the system will know and how reliably it can access that knowledge. The AI will turn raw information into inputs that the system can reason over without making assumptions.
Teams developing AI software will build pipelines with the sanity filter to make sure the model operates on a single source of truth.
After which, the following activities take over.
- Extraction: Pulling data from structured sources such as databases and from unstructured sources like emails or logs for the system’s knowledge boundary.
- Cleaning & Normalisation: Removing “noise” and standardising formats that prevent the model from being confused by inconsistent data entry.
- Deduplication: Identify and remove redundant records that prevent AI from becoming biased toward repetitive data.
- Versioning: Tracking changes in the dataset over time so you can roll back if a new data batch causes the AI to underperform.
- Embedding generation: Converting data into vector form so it becomes easy to search, compare, and retrieve efficiently.
Achieving high-fidelity retrieval requires the AI architecture to adopt a structured approach for balancing broad meaning with specific keyword accuracy.
Here are the strategies with examples.
| Strategy | Technology Examples | Primary Role |
| Dense Embeddings | OpenAI text-embedding-3, Voyage AI, Cohere | Semantic Understanding: When the user asks a question using different words from the source text |
| Sparse Embeddings | BM25, SPLADE, Elasticsearch | Keyword Recall: Excellent for technical jargon, SKU numbers, or specific names. |
| Hybrid Embeddings | Weaviate, Pinecone, Milvus (Hybrid Search) | The Best of Both Uses Reciprocal Rank Fusion to combine results. Provides conceptual depth of Dense and the surgical precision of Sparse. |
Choosing the Model Types
To balance out the latency, cost, and data privacy, teams need to make a decision that typically follows one of three routes, each with distinct practical constraints:
- API Models (Foundation Models): Cheapest and fastest to ship as you get to adopt frontier models like GPT-5.2 or Claude 3.5 via API.
- Fine-tuned Models: Treat it as on-the-job training where you take a powerful model and enhance it using your own domain data. It makes the AI more accurate for your niche and quite cheaper to run, as a smaller, specialised model can often outperform a generic giant.
- Custom-trained Models: Rare and cost-heavy route reserved for highly specialised industries where no existing foundation model understands the underlying data patterns.
Building RAG (Retrieval-Augmented Generation) Properly
RAG works best when systems operate on large volumes of factual data to retrieve information from thousands of documents—policies, SOPs, or technical specifications.
However, RAG becomes a liability when the retrieval noise is too high, causing the model to hallucinate from irrelevant text fragments. One solution is to drive effective chunking — breaking down information that directly affects retrieval quality.
Different strategies serve different needs.
| Strategy | How it Works | Best For |
| Semantic Chunking | Uses embeddings to find topic breaks Splits text only when the meaning of the sentences shifts significantly |
Narrative text: Internal reports, research papers, and complex articles where topics blend. |
| Multi-stride | Creates overlapping chunks (e.g., 500 tokens with 100-token overlap) so that no fact is cut in half | Technical manuals: Ensures specific instructions or code snippets aren’t fragmented across two lookups. |
| Metadata-First | Prioritises document structure (Headers, Tables, Breadcrumbs) | Structured docs: Employee handbooks or legal contracts where a clause is meaningless without its section title. |
Treating Agents as Stateful Objects
AI must be treated as an Object in Object-Oriented Programming, possessing an internal state, private data (memory), and methods (tools).
Some of the core components of an agent are:
- Profile: Defines role, scope, permissions, and tone to prevent the agent from drifting.
- Memory: Stores context that persists across steps or sessions with clear rules for what gets saved.
- Tools: Offer agents the ability to act in systems, not just respond in text.
- Planning: Breaks tasks into steps, chooses tool calls, and decides when to stop or escalate.
Integrating External Tools: The Agent’s Hands
An agent with tools becomes an operator that can move from “talking about work” to “doing work.”
Some of the primary tools are:
- CRMs: To pull account context, update records, log activity, etc
- ERPs: For reading inventory, order status, supplier data, etc.
- Billing systems: Check invoices, usage, refunds, entitlements, etc.
- Search: Enable retrieving internal knowledge or approved external sources
- Code execution: Running calculations, transforming data, validating inputs, etc.
Memory design
When developing Artificial Intelligence software, make sure the memory is designed to prevent agents from restarting on every step. It’s one way to keep the context stable and reduce repeated questions.
Also, the agent maintains context over extended periods to learn from its mistakes and remembers user preferences across sessions.
Here are the three memories and their purposes:
| Memory Type | Role | Practical Application |
| Short-term | Working Memory | Stores the immediate conversation window so the AI remembers what you said 30 seconds ago. |
| Long-term | Hard Drive | Uses Vector DBs to store permanent facts, like a company’s brand guidelines or a user’s birthday. |
| Episodic | Personal Diary | Records specific past sequences of events (e.g., “Last time I tried Tool A, it failed, so I should use Tool B today”). |
C. Take AI Software From Prototype to Production
A giant leap is to move AI software development from pilot to production-grade. But AI software production requires system stability with predictable costs to perform under real-world load.
There are a few major choices to make, along with the action items that follow.
Building an AI Tech Stack
The backbone of AI software lies in the stack you build to run it. The AI stack design determines how requests flow and are routed, as well as the tools involved.
Two primary layers require the tech stack.
i. The Orchestration Layer
Orchestration controls how work flows from user input through actions and tool calls to the final output.
Two patterns dominate.
Chains (LangChain): Best for “Straight-Line” tasks — if A >> B >> C. However, they struggle with “Retry” logic or functions that require looping back to a previous step if an error is encountered.
Graphs (LangGraph/CrewAI): Required for Non-linear, complex decision-making since the graphs treat steps as nodes that can loop back on themselves. For example, when the AI generates code that fails a test, a Graph can automatically route the failure signal back to the generator node to try again.
- The Memory Layer
This one decides what an agent can carry forward between steps and sessions. Many teams stop at a vector database (ideal for semantic lookup), but it does not capture relationships.
Vector databases such as Pinecone or Weaviate are well-suited to finding similar text. But issues crop up when the system demands a relationship structure – what owns what, what depends on what changes, and what applies under which conditions.
What you need here is —
- GraphRAG (Knowledge Graphs): To add a layer of relationships which map entities (People, Products, Companies) and their connections (“John Doe” >>IS_CEO_OF >> “ABC Corp”). It combines vector search and lets the AI follow a chain of facts to answer complex questions that a single document can’t resolve.
For starters, here’s what your pro AI development stack should look like:
| Feature | The Rookie Stack (MVP) | The Pro Stack (Production) |
| Orchestration | Linear chains / Hard-coded logic | Stateful Graphs (LangGraph, CrewAI) for Prompt Optimisation |
| Prompting | Manual “Vibe-based” Prompting | DSPy / Optimisers (Programmatic prompts) for Graph-based orchestration with branching, retries, and state checkpoints |
| Memory | Stateless / Basic Chat History | Managed State & GraphRAG |
| Retrieval | Basic Vector Search | Hybrid Search + Knowledge Graphs |
| Deployment | Single Model API for a few ad-hoc API calls | Model Routers (GPT-4o for logic, Llama-3 for speed) |
| Observability | Basic logs | Automated Evals & Hallucination Scoring |
Evaluate AI systems: automatic + human loops
At this stage of AI software development, the team should assess whether the system can perform consistently under pressure. Because LLMs are non-deterministic, you cannot rely on a single “pass/fail” check.
Instead, you must build a dual-track system:
1. Automated Tests
Enables running thousands of simulations to catch regressions before they reach your users. A common starting point is creating 50 to 100 QA pairs.
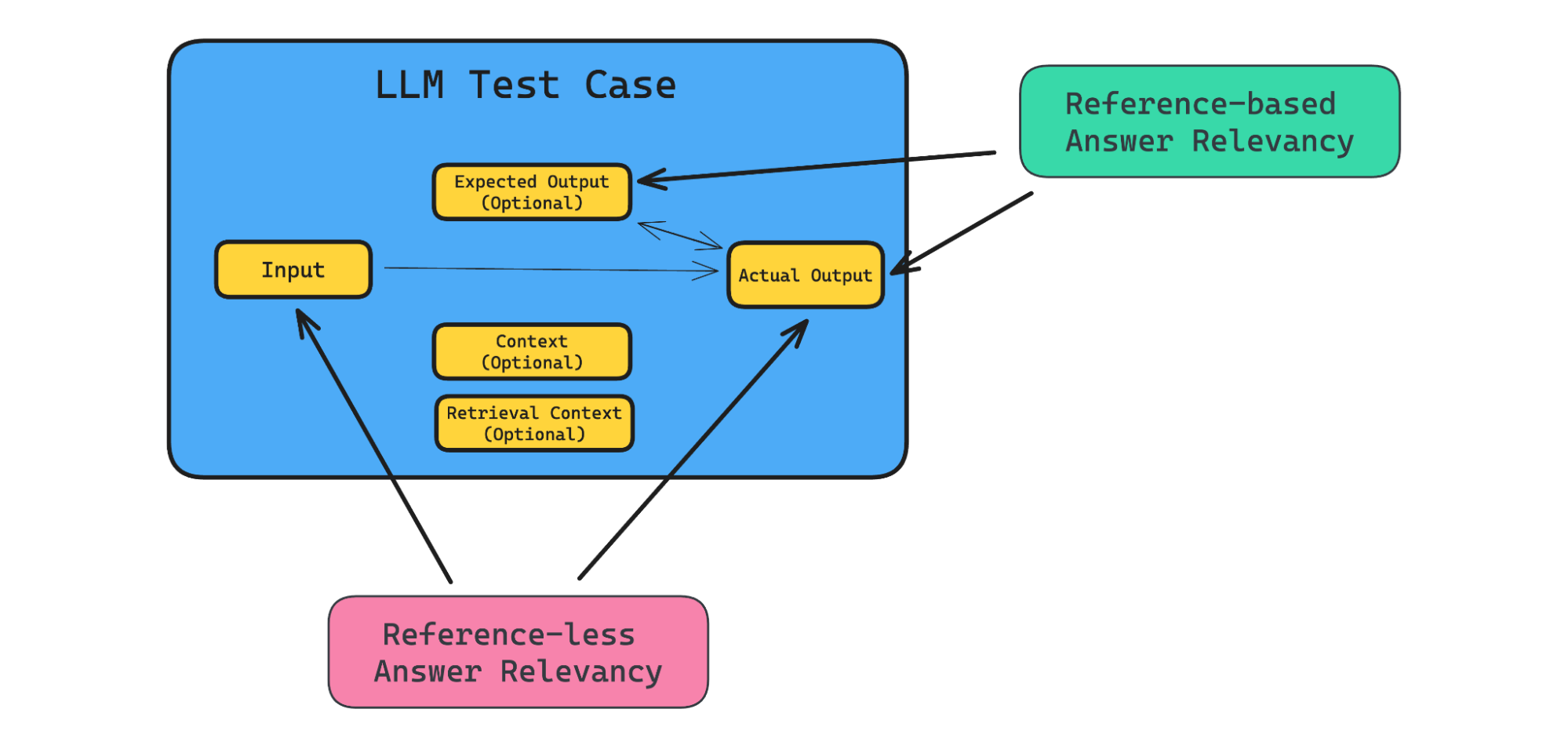
- Input: A specific user query or edge case.
- Expected Output: The ground truth answer or action.
- Acceptable Range: The semantic or structural criteria for success (e.g., “Must contain the refund amount” or “Must use a professional tone”).
Core Testing Types:
- Regression Tests: Check that new changes do not break behaviour that previously worked.
- Adversarial Tests: Probe edge cases, misuse, or ambiguous inputs to see where the system fails.
- Safety Tests: Automated checks to ensure the AI never leaks PII (Personally Identifiable Information) or generates prohibited content.
2. Human-in-the-Loop (HITL)
A mandatory structural pause where the AI must wait for a person to verify an action before execution. It is the final defense against high-impact hallucination-led errors.
Human approval remains mandatory for actions such as:
- issuing refunds
- triggering financial transactions
- deleting records or accounts
- making decisions that directly affect customers
Ensure Cost Control
As enterprise AI usage shifts from experimentation to mass deployment, uncontrolled token consumption can turn a profitable product into a financial liability. This calls for deliberate controls to ensure spending doesn’t outpace usage.
Understanding where the “leaks” are is the first step toward stabilisation:
- Model Selection: Newer models like GPT-5.1 or Claude 4 for basic tasks can inflate budgets without improving outcomes.
- Token Budgets & Latency: Without model routing, systems often over-rely on expensive reasoning models when lightweight models may suffice for handling classification or intent detection.
- Context Window Waste: Passing the full conversation history or large documents on every call quickly burns tokens. Most of that context goes unused.
- Routing Inefficiency: A lack of intelligent logic to decide which model gets which task leads to compute bloat.
AI Team: Build Internally vs Outsourcing
It’s only natural to face trade-offs when building AI software in 2026—should you make it in-house or hire an external partner? It shapes delivery speed and the level of control the organisation retains over the system.
If you’re onboarding talent internally, here’s who you need in the team for AI software development.
| Role | Responsibility |
| AI Product Leader | Translates business goals into AI roadmaps |
| MLOps Engineer | Manages model deployment and monitoring |
| Data Architect | Builds the pipelines for RAG and feature stores |
| AI Quality Council | Audit models for bias and hallucination |
Why Companies Outsource AI Development in 2026
Outsourcing in AI software development does not occur because of the conventional need for cheap labor, but to access specialised speed.
Companies outsource to reduce time-to-launch and access ready-made AI capabilities without incurring the cost of hiring and retaining specialist talent.
Some of the other primary reasons are:
- Fastest path to launch: Specialised agencies use tried-and-true frameworks to deploy working pilots in weeks rather than months.
- Plug-and-play AI teams: Gain immediate access to a full stack without the overhead of individual hiring.
- Cost-effective access to talent: Outsourcing enables access to niche skills that are too expensive to maintain at full-time salaries.
- Reduced risk: External partners absorb the initial R&D risk, allowing for proof of concept before committing to a permanent headcount.
The Build vs. Buy Framework
Before committing to a path, you must weigh the Control vs. Speed trade-off. While buying an off-the-shelf solution is faster, it can lead to vendor lock-in that limits your future flexibility.
| Decision | Best Path | Reasoning |
| Competitive Advantage | Build | If the AI creates your Moat, you must own the IP |
| Internal Tooling | Buy | For non-unique tasks (like invoice processing or customer support), off-the-shelf tools are cheaper |
| Niche/Specific Requirements | Build (or Boost) | Ideal if your industry has strict data privacy rules |
| Rapid Market Testing | Outsource/Buy | Useful to validate a business idea quickly with minimal upfront capital |
Rule of Thumb:
If the AI delivers your primary competitive advantage — build it.
If it is merely internal tooling on how you operate, buy it.
Real-World Examples
Companies are already moving ahead with their own versions of AI. In 2026, there’ll be significant practical AI implementation beyond experimentation.
Take a look at how these UK-based and global leaders are leveraging the AI stack to gain a competitive edge:
1. NatWest – Cora+ (OpenAI + IBM)
NatWest became the first UK bank to partner with OpenAI to transform its digital assistant, Cora+. Originally built on IBM’s WatsonX, the system was deepened in 2025 to handle high-stakes banking tasks.
The bank reported a 150% improvement in customer satisfaction and a significant reduction in the need for human intervention for routine inquiries.
2. Wayve – Embodied AI
Often described as a GPT for driving, its systems learn end-to-end driving behaviour using camera data alone. Instead of relying on handcrafted rules, Wayve trains models through reinforcement learning to respond to real-world conditions.
Unlike traditional self-driving tech that relies on expensive HD maps, Wayve uses a single neural network to see and think.
3. Metaview (Used by Cockroach Labs)
Metaview uses a suite of connected agents to transform raw interview data into structured hiring intelligence. It is used by teams such as Cockroach Labs to turn interview recordings into structured insights that hiring panels can review to solve the administrative bloat in recruitment.
At Cockroach Labs, the recruiting team saved over 14 full working weeks of manual labor. This allowed recruiters to stop acting as note-takers and become strategic hiring partners.
Conclusion
AI software in 2026 no longer hinges on picking the right model. The real advantage lies in building systems that retain context, use tools, retrieve facts, and behave predictably in production.
If you are a founder, CTO, or business leader, your competitive advantage now comes from shifting your mindset from experimentation to engineering discipline. The winners of the next decade will not be those who use the most innovative model, but those who build the most robust systems around them.
Ready to take the next big AI step?
Consult our AI experts to get started.


